
(图1. 通用OCR模型须“通用”)
OCR技术一直是人工智能领域中接近实际应用的研究方向,它代表了AI-1.0时代的技术成果。随着以LLM(Large Language Models)为核心的AI-2.0时代的到来,OCR技术成为了多模态大型模型的一项基础技能,各大模型纷纷投入资源进行研发。尽管多模态大型模型似乎在OCR领域具有压倒性优势,但我们认为,专注于OCR的研究远未结束,实际上可能才刚刚起步。让我们来探讨一下AI-1.0时代的OCR系统和LLM OCR的不足之处:
AI-1.0时代的OCR系统采用的是流水线式设计,各个模块相对独立,虽然局部优化,但维护成本较高,且缺乏通用性,不同的OCR任务需要不同的模型支持,这在实际应用中并不方便。那么,多模态大型模型在纯粹的OCR任务中又存在哪些缺陷呢?
- 为了提升模型的推理能力,必然会导致图像token数量过多,这在OCR任务中可能成为瓶颈。为了获得更好的推理能力,模型需要将图像token处理得更像文本token,以便LLM能够更好地处理。但这样做会导致在处理大量文本时,模型变得复杂且效率低下。例如,一页PDF文档可能需要数千个图像token来处理,这对于模型来说是一个巨大的挑战。
- 另一个直观的问题是模型规模过大,导致迭代更新困难。引入新的OCR特性,如支持新的语言,需要对视觉编码器进行预训练或后训练,这需要大量的资源,对于OCR的需求来说过于奢侈。
GOT:迈向OCR-2.0
我们提出了一个全新的概念——通用或广义OCR(OCR-2.0),并设计了第一个起步模型GOT(General OCR Theory)。这个模型旨在实现输入输出的通用性,支持所有人造信号的识别,并能够输出纯文本以及格式化文本,如Markdown。
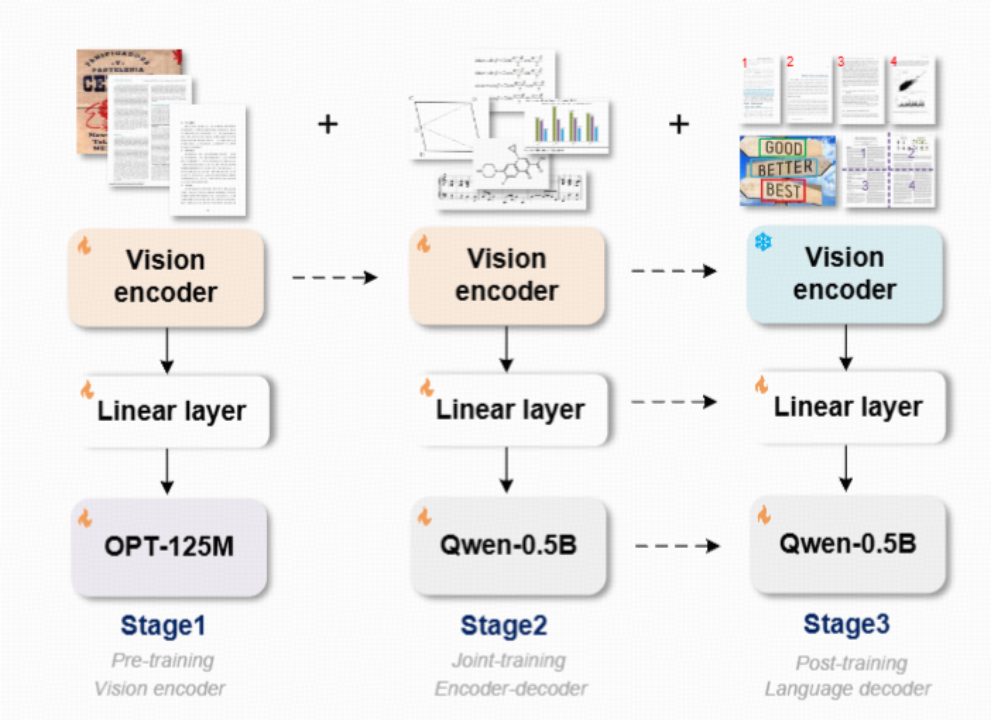
(图2. GOT结构与训练流程图)
GOT模型结构与训练流程
GOT模型的结构和训练方法如图2所示,采用了视觉编码器+输入嵌入层+解码器的流水线结构。编码器采用了带有局部注意力机制的VITDet架构,以避免CLIP方案中的全局注意力在高分辨率下占用过多显存。编码器将1024×1024×3的图像压缩为256×1024的图像token,足以处理A4纸级别的密集OCR任务。
训练过程分为三个阶段,没有锁定LLM,避免了图像到文本对齐阶段可能对图像token的文字压缩率造成损害。这三个阶段分别是:
- 高效预训练编码器,使用小型OPT-125M作为解码器,为编码器提供优化方向,快速处理大量数据。
- 联合训练编码器-解码器,使用预训练好的编码器和Qwen团队预训练的Qwen0.5B,适当增加解码器的大小以处理OCR-2.0的复杂数据。
- 锁定编码器,加强解码器以适应更多OCR应用场景,如支持坐标或颜色引导的细粒度OCR,动态分辨率OCR技术,以及多页OCR技术。
数据工程的挑战
GOT模型设计中最困难的部分是数据工程。为了构建多样化的数据,我们学习并使用了多种数据渲染工具,如图3所示,包括LaTeX、Mathpix、Markdown-it、Matplotlib、Tikz、Verovio、Pyecharts等。

(图3. GOT使用到的数据渲染工具)
结果可视化
GOT模型的输出可视化效果如下:

- 例1:PDF图像转Markdown能力

- 例2:双栏文本感知能力

- 例3:自然场景及细粒度OCR能力

- 例4:动态分辨率OCR能力

- 例5:多页OCR能力
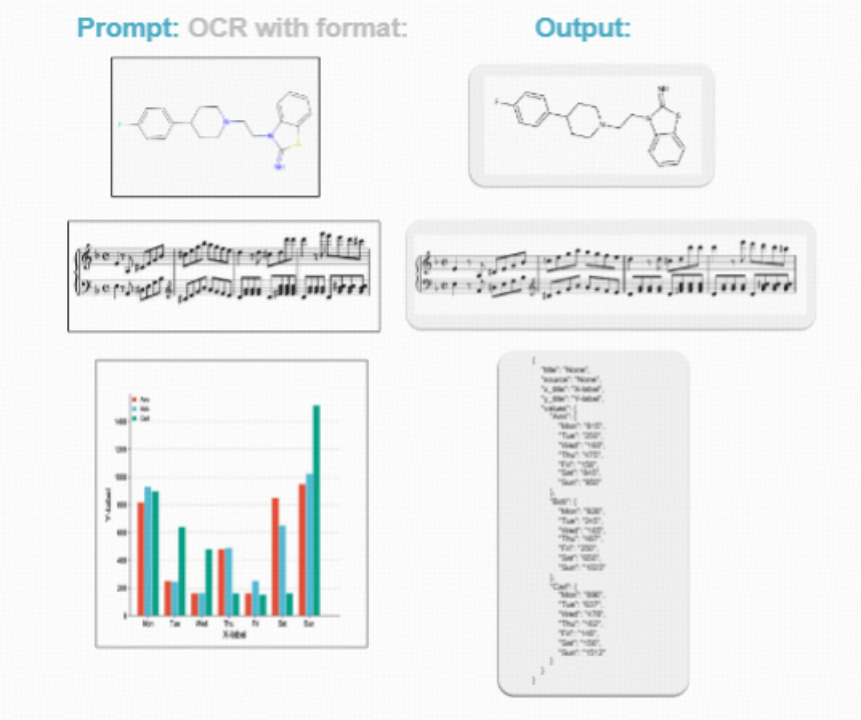
- 例6:更多符号的OCR能力
总结
尽管GOT模型表现出色,但仍有提升空间,如支持更多语言、处理更复杂的几何图形和表格。OCR-2.0的研究还有很长的路要走,GOT项目在数据和算力资源上也受到限制。我们希望通过开源GOT,吸引更多人放弃VQA,转而投入到强感知的研究中。纯OCR虽然容易受到批评,但这正说明我们还有改进的空间。







