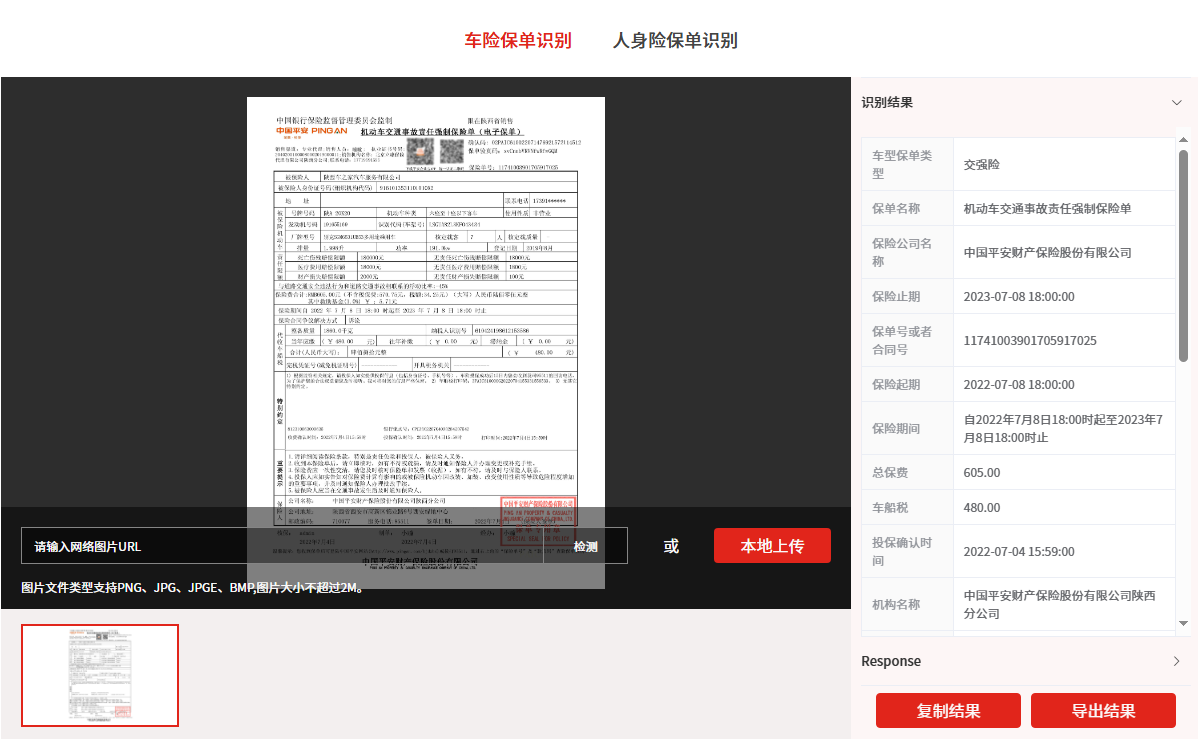
面对格式复杂的车险保单,融合NLP的智能OCR系统将识别准确率提升至98%以上,实现从“图像”到“业务数据”的秒级转换。
在保险理赔、保单贷款和汽车金融等业务场景中,保单信息录入一直是行业数字化的关键瓶颈。传统人工录入方式需要5-10分钟处理单张保单,且准确率仅约95%。而车险保单OCR技术的出现,正彻底改变这一局面。
一、车险保单处理的三大技术挑战
版式多样性是首要障碍。国内有数十家保险公司,每家公司的保单模板各不相同,字段排列顺序差异巨大。商业险保单包含复杂非标准表格,如双栏表格、合并单元格及缺少线框的表格,传统OCR难以稳定识别。
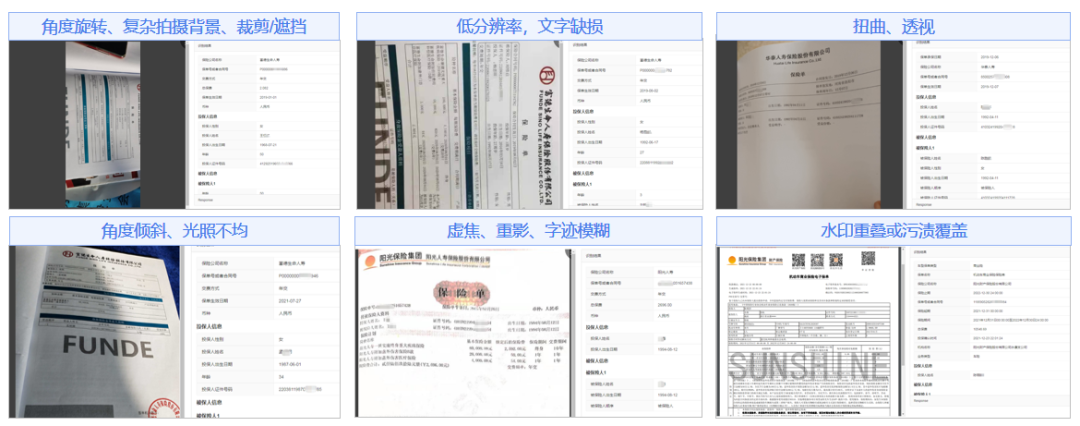
图像质量挑战来自实际应用环境。纸质保单在拍摄时容易出现褶皱、污损、倾斜、散焦等问题。同时,红色印章、骑缝章与印刷体文字重叠,严重干扰文本行检测。
金融级精度要求是最大挑战。保单中的金额、时间、车牌号等关键信息,一个字符错误就可能导致整个业务流程失败。这对识别精度提出了近乎苛刻的要求。
二、金融级精度:NLP与OCR融合的技术突破
语义理解与字段关联分析是提升准确率的核心。通过自然语言处理技术,系统不仅能识别文字,还能理解字段间的逻辑关系。快瞳车险保单OCR技术综合识别准确率已突破98%。
以下是语义解析器的核心实现框架:
import torch
import torch.nn as nn
from transformers import BertModel, BertTokenizer
class InsurancePolicyParser(nn.Module):
def __init__(self, model_name='bert-base-uncased'):
super(InsurancePolicyParser, self).__init__()
self.bert = BertModel.from_pretrained(model_name)
# 条款分类器识别保险责任、免责条款等
self.clause_classifier = nn.Linear(self.bert.config.hidden_size, 10)
# 关键信息抽取器
self.entity_predictor = nn.Sequential(
nn.Linear(self.bert.config.hidden_size, 128),
nn.ReLU(),
nn.Linear(128, 7) # 识别金额、日期、车牌等关键实体
)
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
pooled_output = outputs.pooler_output
# 语义理解与信息提取
clause_logits = self.clause_classifier(pooled_output)
entity_logits = self.entity_predictor(pooled_output)
return clause_logits, entity_logits
该解析器利用深度学习模型理解保单语义,识别关键条款和实体信息。通过自然语言处理技术,系统能够理解保险术语的特定含义,如同义词归一并关联相关字段。
三、专业技术突破:深度学习与语义理解的融合
针对行业痛点,通过深度学习OCR引擎与自然语言处理技术的结合,实现了对车险保单内容的深层次解析。系统采用专为保险行业训练的识别模型,具备三大技术优势:
1. 多保险公司版面的强大适应性
基于自研深度学习算法,该系统已预训练学习超过40家保险公司的保单模板,能够自动适应不同版式,准确识别交强险和商业险的全量字段。无论是电子保单、纸质保单还是PDF文件,系统都能实现精准解析。
2. 语义理解与字段关联分析
通过自然语言处理技术,系统不仅能识别文字,还能理解字段间的逻辑关系。例如,系统可以验证“保险止期 > 保险起期”、“总保费 = ∑各险种保费”等业务规则,确保识别结果的合理性。内置的保险知识库还能自动校正“众安/众诚/众海”等易混淆保司名称,将“车上人员责任险(司机)”统一成标准字段“司机座位责任险”。
3. 图像预处理与纠错能力
针对印章干扰和图像质量问题,系统采用先进的图像处理算法,能够自动检测印章区域并进行智能擦除和修复,同时对倾斜、弯曲、光照不均的图像进行自动校正,保证识别稳定性。
四、技术演进:专用模型与通用大模型的协同之道
面对当前通用大模型免费开源的趋势,专用OCR技术展现出不可替代的价值。通用大模型在OCR领域存在三大局限:“幻觉”问题可能导致关键信息错误识别;处理速度较慢,百亿级参数处理单张A4保单需要10秒起步;提示词设计复杂,业务人员难以掌握。
快瞳科技采取的是“专用小模型+通用大模型”的协同路径。专用OCR模型负责感知与精准识别,其输出的高质量结构化数据可作为通用大模型的输入,支撑更复杂的核保、定损、咨询等智能决策任务,实现优势互补。
该系统还支持多页PDF处理和复杂表格解析,能够准确识别交强险、商业险等不同类型保单的全量字段,包括车架号、保险公司全称、保险期间、被保险人、保险单号等关键信息。
五、未来展望:保险数字化的技术基石
随着技术的发展,快瞳车险保单OCR正从单纯的文字识别向语义理解与知识提取迈进。未来的系统将不仅能识别文字,还能理解保险条款的法律含义,自动进行合规性检查和风险评估。
这种技术突破不仅意味着效率提升,更是整个保险业务流程的智能化重构。它为精准定价、智能核保、自动放款等场景提供了可靠的数据底座,推动整个行业向数字化、智能化方向迈进。
目前,该技术已能够实现全国所有保险公司各类纸质和电子保单的全字段自动化识别与提取,为保险行业的数字化转型提供了坚实技术基础。







