在银行业,OCR技术已经成为票据处理的重要工具。随着数字化转型的加速,OCR技术的应用也在不断扩展,提高了票据处理的效率。
早期OCR技术的应用
早在几年前,随着业务数字化需求的增加,OCR技术被引入银行业务系统,极大地提高了票据录入的效率。OCR技术的应用使得原本需要手工录入的工作得以自动化,显著减少了人力资源的投入。

OCR技术面临的挑战
尽管OCR技术在识别固定版式的证件和票据方面表现出色,但在面对银行业务中长尾场景下的复杂识别任务时,其能力就显得不足。特别是在遇到版式不固定、样本量少的票据,以及包含手写体、多语言和特殊字符的文档时,识别准确率会大幅下降。
多模态融合技术的发展
为了提升OCR模型的泛化能力,解决版式不固定和识别准确性的问题,多模态融合技术应运而生。这种技术融合了视觉信息、语义信息和布局排版信息等多种模态,提升了模型的识别能力。通过大规模的多模态文档预训练,模型能够支持超过5000种以上的版式,极大地提高了OCR技术的泛化能力。
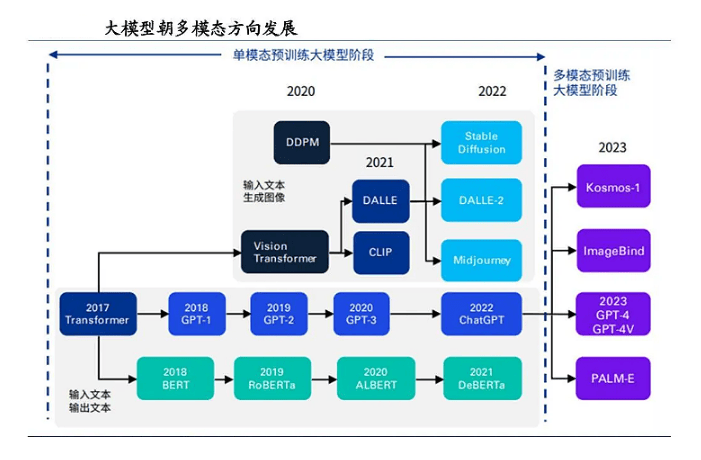
多模态融合技术如何提升OCR的识别度
信息融合:
多模态技术结合了视觉信息(图像中的文字和图形)、语义信息(文字的含义和上下文关系)和布局排版信息(文字的位置和排列方式),这种融合提供了比单一模态更全面的数据分析,从而提高识别的准确性。
预训练模型:
在大规模多模态文档预训练的基础上,模型能够学习到不同版式、不同语言和不同场景下的文字特征,这使得模型在面对新的、未见过的版式时也能保持较高的识别准确率。
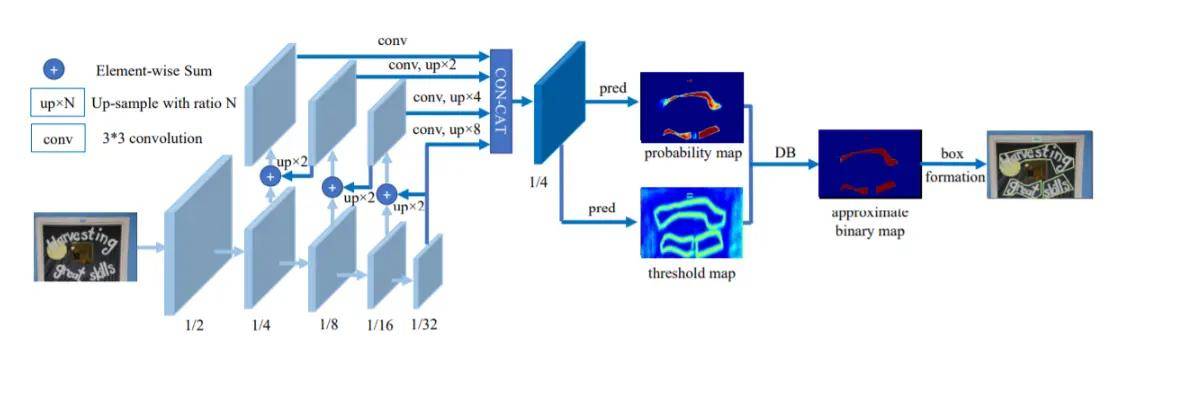
结构化信息提取:
多模态技术能够更好地理解和提取文档中的结构化信息,例如表格、列表和段落,这对于复杂文档的识别尤为重要。
版式适应性:
多模态模型能够适应多种版式,包括那些版式不固定或样本量较少的情况,因为它不仅仅依赖于版式匹配,而是能够理解文档的深层结构和内容。
复杂关系提取:
对于包含复杂关系(如表格中的行和列关系)的文档,多模态技术能够更好地识别和理解这些关系,从而提高结构化信息提取的准确性。
上下文理解:
通过语义信息的融合,模型能够更好地理解文字的上下文含义,这对于提高手写体文字和多语言文档的识别准确率尤其重要。
模型泛化能力:
多模态模型通过训练学会了如何泛化到不同的文档类型和场景,这意味着它能够识别和适应各种不同的文档,而不仅仅是训练时见过的那些。
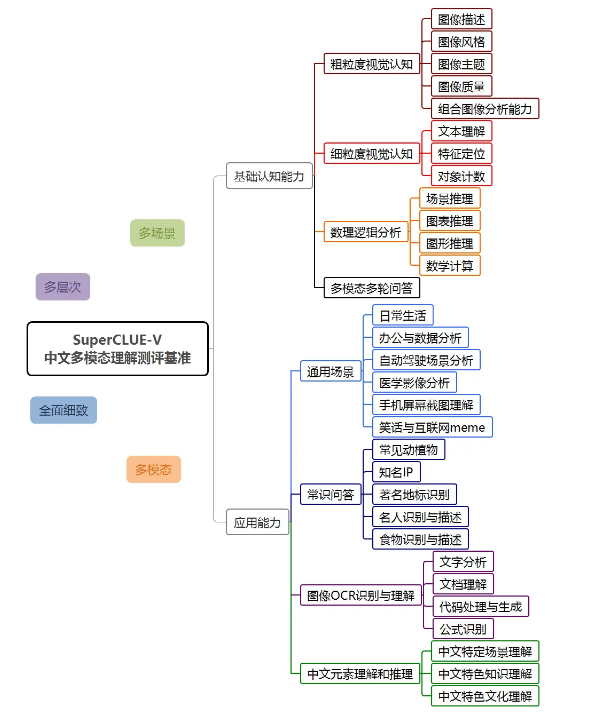
持续学习:
多模态模型可以持续学习新的版式和特征,通过不断的训练和优化,模型能够适应新的挑战,提高识别准确率。
错误纠正机制:
多模态技术可以结合错误纠正算法,通过分析上下文和语义信息来自动纠正识别过程中的错误。
综上所述,多模态融合技术通过综合利用不同类型的信息,提高了模型对文档的理解和识别能力,从而显著提升了OCR技术的准确率。







